
How Amazon S3 Stores Data

I’m pretty sure many of you have used or at least heard of Amazon S3 — it’s one of those things that just "works" and quietly powers a huge chunk of the internet. Whether you're backing up photos, storing logs, or serving video files, S3 is often the go-to object store.
But have you ever stopped to ask:
“How the heck does S3 store data so reliably and at such insane scale?”
That’s exactly what we’re diving into today.
Wait... Is S3 a Database?
Not quite. S3 is an object storage service, not a relational or NoSQL database. But that doesn’t mean it isn’t doing a ton of “DB-like” things under the hood. In fact, it’s a beautifully engineered distributed system with custom-built storage mechanisms that combine the best ideas from databases, filesystems, and distributed computing.
Think: Dynamo + Erasure Coding + Chunked Blob Store + Metadata DB all stitched together into a storage beast.
🔍 So What Is Actually Stored in S3?
Every object you upload to S3 has two parts:
- Metadata – your object’s key, creation date, version, access control, etc.
- Binary Data – the actual file content (image, zip, video, log, etc.)
These are stored separately.
🧠 The Metadata Store (Dynamo-ish)
The metadata — all the "what, when, where" info — is stored in an internal, highly available key-value store. From everything we know (based on AWS papers and talks), this is built using Dynamo-style distributed hashing and quorum-based replication.
- Every object key (e.g.,
images/puppy.jpg) becomes a key in the system. - The value includes pointers to where the actual object chunks live.
- The metadata DB handles versioning, ownership, ACLs, timestamps, and more.
This layer is optimized for low-latency reads and writes and replicated across multiple availability zones (AZs).
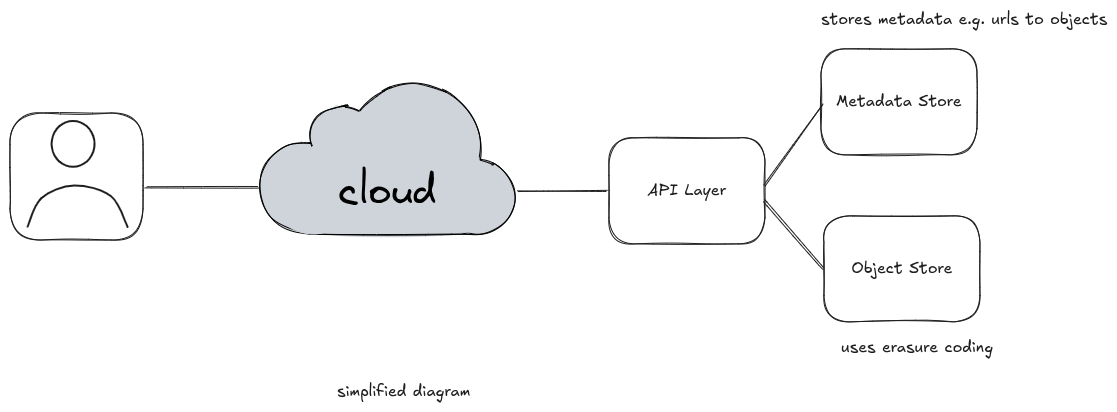
🧱 The Object Data Store (Chunked & Distributed)
When you upload a file, S3 splits it into chunks behind the scenes. These chunks are then:
- Erasure coded (not just replicated — more on this in a second)
- Distributed across multiple physical disks
- Stored in different availability zones, often even different racks and buildings
Why? So even if an entire AZ goes down, your data is safe.
📦 Erasure Coding 101
This is the real magic. Instead of just making 3 full copies of your file (which is expensive), S3 uses erasure coding, which works like this:
- Break your data into
kparts - Generate
mextra parity parts - You can lose up to
mchunks and still recover the file
For example:
- File split into 10 data chunks
- 4 parity chunks added
- You can survive 4 failures, while storing only ~1.4x the original size (vs 3x for full replication)
That’s cheaper and more durable.
NOTE: This is bit too big to explain in detail here and require its own dedicated post 🙂
📈 Performance + Durability
Amazon promises 11 9’s of durability (yes, 99.999999999%). Here’s how they pull that off:
- Redundant storage across 3+ AZs
- Automatic background checks and repairs
- Erasure coding to reduce storage overhead
- No single points of failure
- Anti-entropy services that constantly validate and heal corrupted chunks
You’ll probably never even notice all this happening — and that’s the point.
🧾 Read-After-Write Consistency? Yep, Now It’s Strong.
Until 2020, S3 was eventually consistent for overwrites and deletes. That’s changed.
Now S3 offers strong read-after-write consistency by default for new objects, thanks to upgrades in the metadata layer — likely powered by stronger quorum protocols.
This means:
- Once you upload a file, any subsequent read from any region will get the latest version.
- No waiting for propagation.
It’s a small change on the surface, but a huge architectural leap under the hood.
⚠️ So… Is It Using Any Known DB?
Not directly. S3 doesn’t use off-the-shelf databases like MySQL or Cassandra.
Instead:
- Metadata DB → custom key-value store inspired by Dynamo
- Object data → stored in a distributed chunked file system
- Durability → via erasure coding + replication
- Consistency → via quorum-based metadata writes
The system is designed to handle exabytes of data, across millions of disks, while being fault-tolerant, eventually consistent (with strong options), and blazing fast.
💡 What Can We Learn From S3?
S3 is a case study in purpose-built design.
- Separate metadata from data
- Use erasure coding instead of brute-force replication
- Build for failure — expect disks, racks, and entire zones to fail
- Decentralize and shard everything
- Eventually consistent is often good enough — until it isn’t
Whether you're building a file store, a video platform, or a custom backup system — these lessons are gold.
Conclusion
S3 isn’t “just a bucket” — it’s a carefully engineered distributed storage fabric that runs one of the largest infrastructures in the world.
The takeaway: next time you're storing even a few gigabytes of data, think like S3.
Design for failure. Decouple metadata. Keep it simple, but make it solid.
Want to dive deeper into how other hyperscalers do storage? Ping me and I’ll write about GCP, Azure Blob, or even open-source equivalents like MinIO and Ceph.
Until then — happy storing.
The Dev Learnings Team
Member discussion